About a year ago I tried to build a voice-based knowledge management system. You know, the thing everybody wants. The perfect assistant that sits in the corner, takes care of notes and followups like recording action items, conducting further research, linking to resources, and more.
During this process,I distilled some frameworks for thinking about voice-based technology that might be helpful to folks thinking about pursuing this same path. My takeaways about speech boil down to:
- How it works.
- What it does well.
- Where it has limitations.
The ideas in section one will allow you to create your own working model of the technology for nuanced applications of two and three.
How Speech Technology Works
Speech technology involves a long pipeline that takes vibrating air molecules and turns them into computer actions. Each step requires different pieces of technology and has its own quirks.
Think of voice tech not as a monolithic entity but instead a pipeline of different technologies. Recently, deep learning has drastically improved some parts of this pipeline, but others are still using technology from the 90's or before.
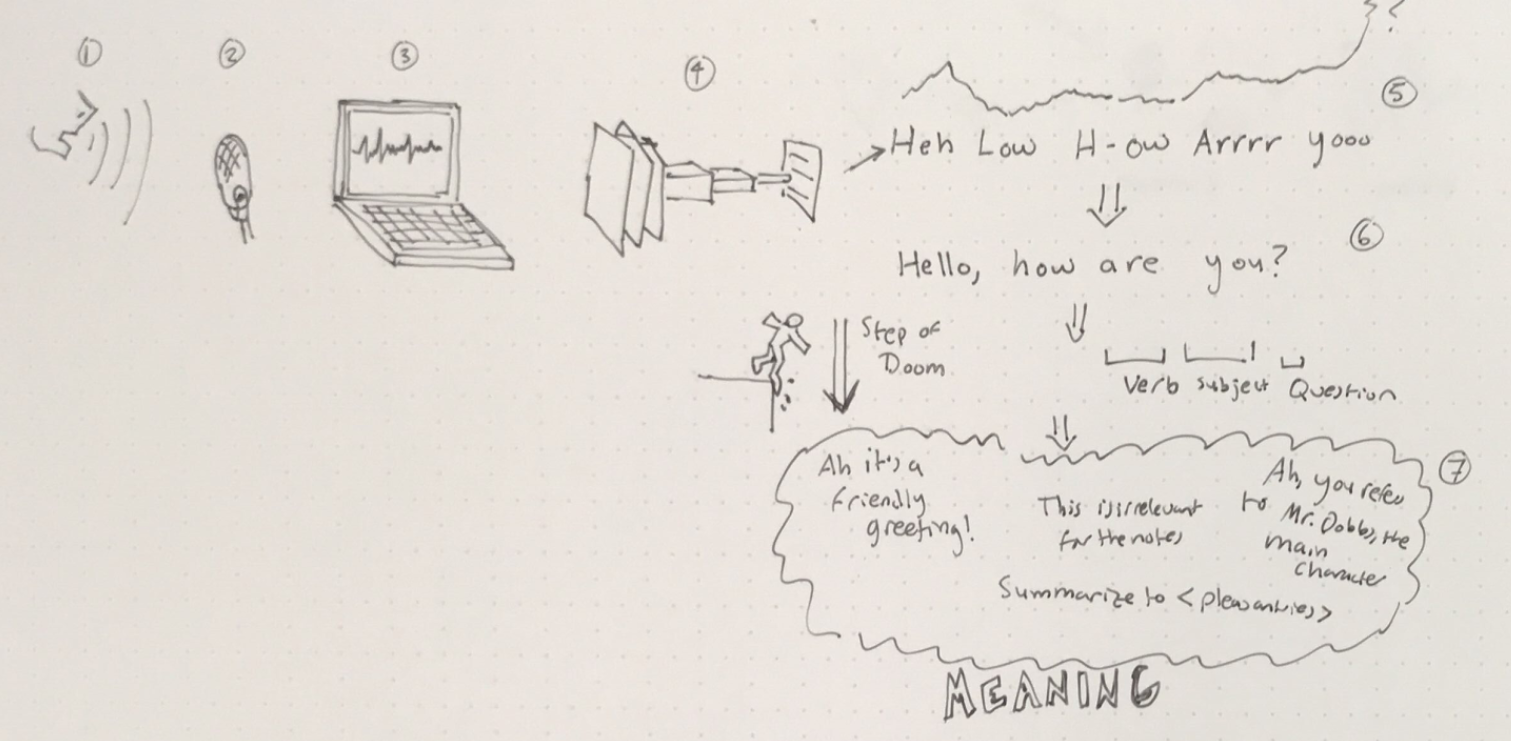
(1) Sound Waves -> (2) Capture and Digitze -> (3) Digitized Audio -> (4) Automatic Speech Recognition(ASR) / Speech to Text (S2T) -> (5) Words -> (6) Natural Language Processing(NLP) -> (6) Parts of Speech, Topics, etc. -> (7) Logic -> Actions
1. Sound Waves
These are the raw sound waves coming into the device.1
2. Capture and Digitize the Sound
In this step, the audio is physically captured and transformed into digitized audio. It's complicated, but essentially the sound waves vibrate something like an electromagnet or piezoelectric crystal that produces a voltage and an analog-to-digital converter turns that voltage into a digital recording.
There are several factors in sound capture that affect steps further down the pipeline:
- Number of speakers: more people speaking per capture device makes it more difficult to pick out single voices.
- Capture Device: quality makes a difference! Phone speakers vs. worn microphones vs. conferencing systems.
- Sample rates: high sample rates create better data but require much more compute and storage
- Where the sound real-world noise is coming from: speech recognition on far field audio is harder. Far field audio is audio produced relatively far from the capture device, like someone talking from across a table. It is harder to use for two reasons: the environment affects the sound more and there just aren't as much training data out there.
- What else is making noise in the same space - environmental noise can kill speech applications.
3. Digitized Audio
This is the audio stored on the computer/server or streaming from a source. If it's being stored, space is a concern, if streaming, speed is a concern.
4+5. Recognize the Speech and Try to Convert into Words
Otherwise known as Speech to Text (S2T) or Automatic Speech Recognition (ASR)
The process of turning the audio into a stream of words (sometimes with punctuation.) Right now every speech application uses this as an intermediate step as opposed to an end-to-end application that does actions based directly on the audio. This is the first step that uses a Deep Network.
Usually it's a two-step process. First a network turns the audio into Phonemes and then classifies blocks of phonemes into words. Some companies like Deepgram work directly with phonemes and never go to words.
The more words you're trying to classify the phonemes into, the harder it is. This is why domain-specific speech recognition is often more accurate, and why Siri is great at recognizing names in your contact list and Alexa is good at recognizing song names.
Word Error Rates (WER) are reported on standard datasets that are usually low-noise recordings of a single person. They're a good baseline, but don't take into account massively different kinds of noise, different capture methods, and number of speakers. You also need to consider the fact that one changed word can change the entire meaning of a sentence or paragraph. See Where Speech Tech Has Limitations for more.
The output of this process is words. Those things you're reading right now that encode language.
6. Interpret Words via Natural Language Processing (NLP)
Turning a sequence of words into "meaning." This can be many different things, but the standard ones are:
- Parts of speech/sentence structure
- Entities
- Similarities between sentences
- Topics
- Intents
It's very hard to say what the topic is if you can't extract it from words already in the text (ie. if you need external context about the world.)3
You can train a network to recognize many different things
Note that "Accurate" for NLP is in the realm of 60%. This is where the contrast between cutting-edge research and consumer-products is stark.
Most NLP is at the word or sentence level. It is still very hard to say meaningful things about entire documents besides "these are the things we found in this document."
7. Decide what to do with the interpreted words (Logic)
This is where you take a big pile of information about the speech and decide what to do with it.
Here's where it's the wild west - there is no deep learning for what logic to perform. Often it is no more than a big pile of IF statements.
8. Take action
This is the good stuff you want at the end of the day. Turning on music, entering data in a database, creating a calendar event, etc. etc.
What Speech Tech Does Well
There are three areas where current speech tech shines. If a speech application falls outside of these categories, beware.
1. It allows you to do computer input without your hands or eyes2
This is the Siris, Alexas, and Hey Googles of the world. Speech processing allows us to get information into a computer without looking at a screen or fiddling with our hands.2
I chose this wording carefully because of the pieces it leaves out. Speech on its own does not unlock the ability to interact with a computer without your hands or eyes. The loop between input and action is still fraught with problems and because there's no visual feedback, the computer either has to annoyingly ask "did you mean blah?" or just do what it thought you meant.
2. It allows you to extract structured data from voice - either pre-recorded or live.
This allows you to possibly fill in forms, figure out what people are talking about, and search through conversations after the fact. When it's important to pay attention to very specific words "Hey Siri", "\<Product name\>" voice shines.
3. Specialized Domains.
The fewer the number of words the speech system needs to recognize, the more accurate it will be on the ones it does know.
Why is this? If you go back to step (4) - neural networks basically ask "given everything I know, what is the most probable word that I can make out of these (often imperfect) phonemes?" With more words to choose from there will both be more words with similar probabilities and also a greater chance that the correct word isn't the most probable one. We say unexpected things sometimes.
Often we recognize unfamiliar or unexpected words by filling in based on context - both the previous and following words, the topic of conversation, and even abstract cultural knowledge. 3 Specializing the domain makes the context explicit - all names of drugs, people from your contacts list, a finite set of tasks, etc. that last the underlying neural nets are trained on examples, so a net that only deals with a few words can specialize
If a product or application falls outside of these categories, it's leaning on areas of technology that haven't necessarily made a giant leap forward thanks to deep learning advances. This includes things like topic extraction and especially getting the computer to take a specific action.
Where Speech Tech Has Limitations
1. Anywhere that errors are unacceptable.
1% Word Error Rate (WER) sounds great (I wish I was right 99% of the time) until you realize that there's a very big difference between the sentence that you are reading right now and the following one, which together have a Word Error Rate of 2%:
50% Word Error Rate (WER) sounds great (I wish I was right 98% of the time) until you realize that there's a very big difference between the sentence that you are reading right now and the following one, which together have a Word Error Rate of 2%.
2. Uncommon Words
Unfortunately these are often the words - names of people, places, things - that you want to get the most right: everything from notes on a meeting to medication names.
3. Anywhere you want a feedback loop with a person using the system.
Currently, there are two options for feedback, both terrible: the first option is to force someone to look at a screen, which much of the time destroys the utility of using voice in the first place. The second option is to ask for confirmation which is far more annoying from a computer than from a real person.
4.Anywhere context is important
This is the other side to the "speech is good in specialized domains" coin. The difficulty of getting the fuzzy sense of context into AI systems is a topic in and of itself.
5. Trying to make sense of human-human conversations
I've stared at hundreds of raw transcripts of totally normal conversations between two people. They are horrific. Random noises, referring to things five sentences ago, cutting the other person off, cutting themselves off. Even if you did text to speech perfectly, extracting information is still a nightmare. For example:
Person 1: um, so, yeah - that thing we - ok this time we're doing the thing, right? I know -
Person 2: Yeah, I'm on it, but \<pause with some paper scratching that could be transcribed as words\>
Conclusion
Modern speech systems are powerful - if used correctly. They are not magic pixie dust you can sprinkle wherever people are using their voices. Remember that speech processing is a long pipeline that accumulates error at every step. In almost every situation, if it's something that's hard with text, it's even harder with speech because you're doing the same thing but with imperfect text. There are things they are good at and places they fall on their faces. The more you understand how they work, the easier it is to figure out which is which.
Further Reading
- https://digiday.com/media/state-voice-five-charts/ - note that user retention for alexa apps is terrible
- Reasonable article on Investing in Voice - https://medium.com/startup-grind/why-voice-tech-is-about-to-see-major-love-from-vcs-341a9b05cc2b - good point that Software Tools and Applications are where the good investments will be, not the underlying Tech at the bottom of the stack.
- https://www.technologyreview.com/s/602094/ais-language-problem/ Overview of why language is hard for computers
- http://www.interspeech2017.org/areas-and-topics/ Detailed breakdown of each level of the speech stack through the lens of active research. Here are the actual papers so you can see who's working on what http://www.isca-speech.org/archive/Interspeech_2017/
- https://medium.com/startup-grind/the-voice-enabled-revolution-f35f751c2f77 Good company overiew
1 Sound waves are pretty sweet: propagating regions of high and low pressure. But maybe Wikipedia knows more.
2 Aside: a crucial design constraint for speech-based systems is to avoid violating the "no hands or eyes" rule. That is, there should never be a situation where the system forces someone to go from using speech to looking at a screen or typing on a keyboard in the moment. It makes the whole thing useless. A caveat to this caveat is that these rules are slightly different in countries that don't use the roman alphabet because typing is much more of a pain so people often prefer to do speech even while staring at a screen.
3 If I say "once burned, twice “___”; a native english speaker can guess what the last word is with 99% confidence. How cool is that?
If you enjoyed this post, please share!